Spark Python Shell: pyspark
- Spark Context is the main entry point of spark.
- Spark Shell provides a preconfigured Spark Context
sc - RDD-Resilient Distributed DataSet
- Resilient: if data lost in memory, it can be re-created
- Distributed: across the cluster
- DataSet
- RDDs is the fundamental unit of data in Spark
- Three ways to create RDD(RDD is immutable):
- From a file or a set of files (Accepts a single file, a wildcard list of files, or a commaUseparated list of files )
- From data in memory
- From another RDD
- Two types of RDD operations:
- Actions: return values
- count()
- take(n)
- collect()
- saveAsTextFile(file)
- first – return the first element of the RDD
- ???foreach – apply a funcDon to each element in an RDD
- top(n) – return the largest n elements using natural ordering
- takeSample(percent) – return an array of sampled elements
- Double options: Statistical functions, e.g., mean, sum, variance, stdev
- Transformations: define a new RDD from existing one
- map()
- filter()
- flatMap – maps one element in the base RDD to mulDple elements
- distinct – filter out duplicates
- union – add all elements of two RDDs into a single new RDD
- sample(percent) – create a new RDD with a sampling of elements
- flatMapValues
- keyBy: Pair RDD Operation
- countByKey: Pair RDD Operation – return a map with the count of occurrences of each key
- groupByKey: Pair RDD Operation – group all the values for each key in an RDD
- sortByKey(ascending=False): Pair RDD Operation – sort in ascending or descending order
- join: Pair RDD Operation – return an RDD containing all pairs with matching keys from two RDDs
- keys – return an RDD of just the keys, without the values
- values – return an RDD of just the values, without keys
- lookup(key) – return the value(s) for a key
- leftOuterJoin, rightOuterJoin – join, including keys defined only in the lek or right RDDs respectively
- mapValues, flatMapValues – execute a funcDon on just the values, keeping the key the same
- Actions: return values
- Lazy Execution: Data in RDDs is not processed until an action is executed
MapReduce in Spark
- MapReduce in Spark works on Pair RDDs
- Map phase
- Operates on one record at a Dme
- “Maps” each record to one or more new records
- map and flatMap
- Reduce phase
- Works on Map output
- Consolidates mulDple records
- reduceByKey
- Pair RDDs are a special form of RDD consisting of Key Value pairs (tuples)
- Spark provides several opera.ons for working with Pair RDDs
- MapReduce is a generic programming model for distributed processing
- Spark implements MapReduce with Pair RDDs
- Hadoop MapReduce and other implementaDons are limited to a single Map and Reduce phase per job
- Spark allows flexible chaining of map and reduce operaDons
- Spark provides operations to easily perform common MapReduce algorithms like joining, sorting, and grouping
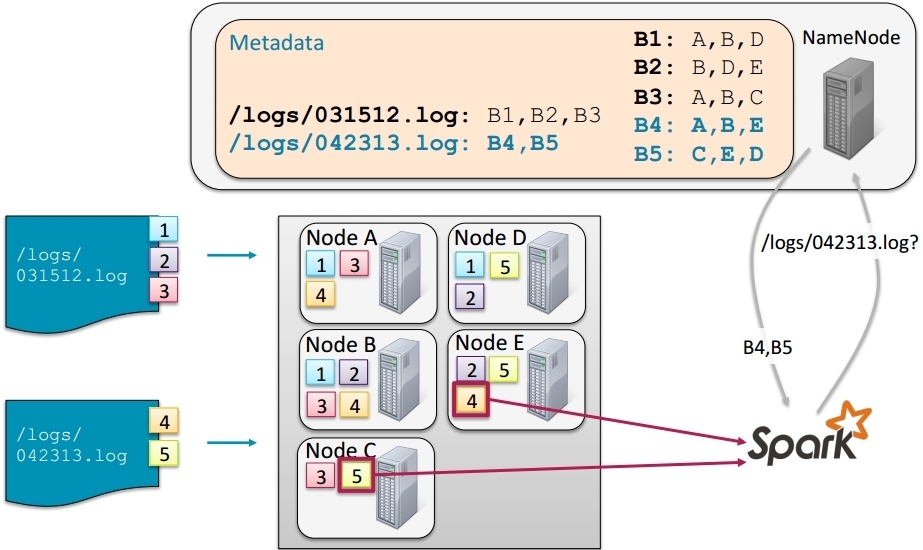
Spark and HDFS
Spark Cluster Options
- Locally: No distributed processing
- Locally with multiple worker threads
- On a cluster
– Spark Standalone (not suggest on production)
– Apache Hadoop YARN
– Apache Mesos
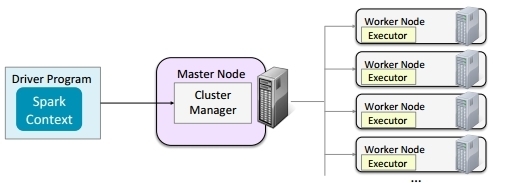
The Spark Driver Program
- The “main” program
– Either the Spark Shell or a Spark application - Creates a Spark Context configured for the cluster
Communicates with Cluster Manager to distribute tasks to executors
Runing Spark on a Standalone Cluster
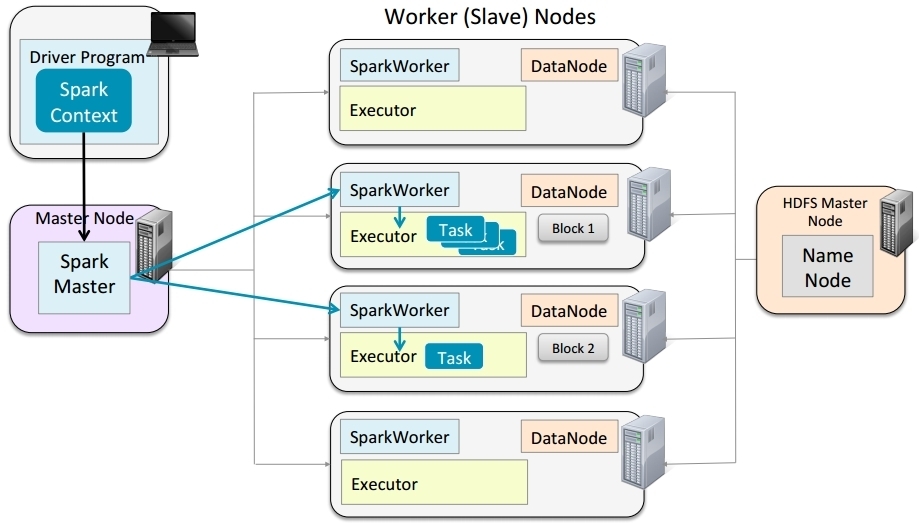
Driver program can run use Client Mode or Cluster Mode
- All cluster options support Client Mode
- Only YARN support Cluster Mode
Key Points:
- Spark keeps track of each RDD’s lineage
- By default, every RDD operation executes the entire lineage
- If an RDD will be used multiple times, persist it to avoid re-computation
- Persistence options
- Caching (memory only) – will reUcompute what doesn’t fit in memory
- Disk – will spill to local disk what doesn’t fit in memory
- Replication – will save cached data on multiple nodes in case a node goes down, for job recovery without recomputation
- Serialization – inUmemory caching can be serialized to save memory (but at the cost of performance)
- Checkpointing – saves to HDFS, removes lineage
Cache
Persistance Level
- The cache method stores data in memory only
- The persist method offers other options called Storage Levels
- Storage location
- MEMORY_ONLY (default) – same as cache
- MEMORY_AND_DISK – Store partions on disk if they do not fit in memory(Called spilling)
- DISK_ONLY – Store all partions on disk
- Replication – store partions on two nodes
- MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc.
- Serialization – you can choose to serialize the data in memory
- MEMORY_ONLY_SER and MEMORY_AND_DISK_SER
- Much more space efficient
- Less time efficient, Choose a fast serialization library
- To stop persisting and remove from memory and disk
- rdd.unpersist()
- To change an RDD to a different persistence level
- Unpersist first
Use cache mode:
Best performance if the dataset is likely to be re-used, example:
myrdd=xx.map(lambda x: x+1)
myrdd.cache()
myrdd.count() # any action will triger the cache

Use cache on disk-only:
When recomputation is more expensive than disk read, example:
from pyspark import StorageLevel
myrdd=xx.map(lambda x: x+1)
# if the RDD object is in cache on above example,
# you should use `myrdd.unpersist()` to unpersist it
myrdd.persist(StorageLevel.DISK_ONLY)
myrdd.count() # any action will triger the cache/persist

Use replication:
When recomputation is more expensive than memory, example:
from pyspark import StorageLevel
myrdd=xx.map(lambda x: x+1)
# if the RDD object is in cache on above example,
# you should use `myrdd.unpersist()` to unpersist it
myrdd.persist(StorageLevel.MEMORY_ONLY_2)
myrdd.count() # any action will triger the cache/persist
Check Point
- Maintaining RDD lineage provides resilience but can also cause problems
- when the lineage gets very long
- e.g., iterative algorithms, streaming
- Recovery can be very expensive
- Potential stack overflow
Check Point is targeting to fix this issue and short the lineage
- Checkpoining saves the data to HDFS
- Lineage is not saved
- Must be checkpointed before any actions on the RDD

Write Spark Application
How to write work
Almost same as shell, normally just reference related libs and create SparkContext on the top
SparkContextnormally named byscfor convention
Code as word count: (wordcount.py)
import sys
from pyspark import SparkContext
from pyspark import SparkConf
if __name__ == "__main__":
if len(sys.argv) < 2:
print >> sys.stderr, "Usage: WorldCount <file>"
exit(-1)
# if you want do define config in code, following comment is the way
# normally, it's better to use separate property file
# sconf = SparkConf().setAppName("My Spark App").set("spark.ui.port", "4041")
sc = SparkContext()
logfile = sys.argv[1]
words = sc.textFile(logfile).flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b);
# Replace this line with your code:
print "Number of words: ", words.count()
Comment:
Scala or Java Spark applica;ons must be compiled and assembled into JAR
files
– JAR file will be passed to worker nodes
Using spark-submit run the code
Detail document see: [https://spark.apache.org/docs/1.2.0/submitting-applications.html]
spark-submit wordcount.py filename
spark-submit --master spark://localhost:7077 ~/training_materials/sparkdev/stubs/CountJPGs.py /user/training/weblogs/* --properties-file spark.properties |
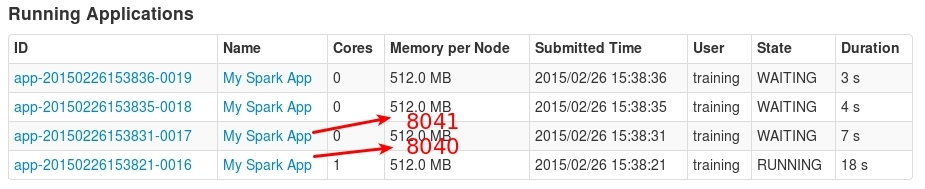
Running multi-jobs at the same time
References: