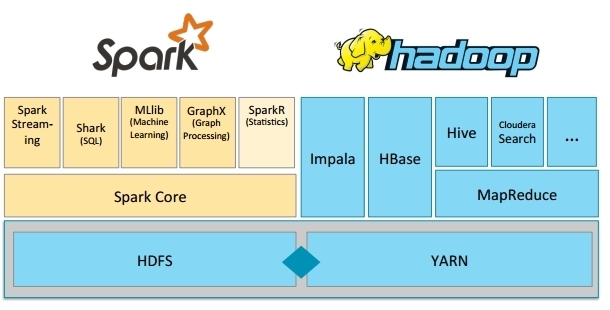
Spark Stack
Spark was created to complement, not replace, Hadoop
- Uses HDFS
- Runs on YARN
- Integrate well with Hadoop ecosystem (flume/sqoop/hbase, in future and kafka)
Hadoop introduced two key concepts:
- Distribute data
- Run computation where the data is
Spark take it to the next level and make data distributed in memory.
Spark Framework
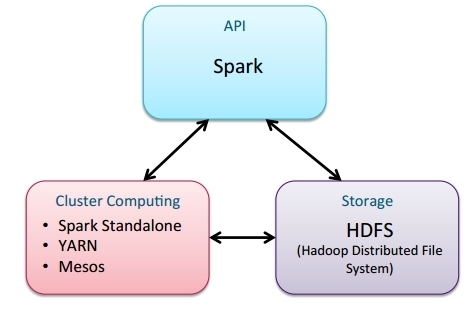
- Cluster computing
- Application processes are distributed across a cluster of worker nodes
- Managed by a single “master”
- Scalable and fault tolerant
- Distribute storage
- Data in memory
Common Use Case
- ETL
- Text mining
- Index building
- Graph creation and analysis
- Pattern recognition
- Collaborativce filtering
- Prediction models
- Sentiment analysis
- Risk assessment
Spark VS Hadoop MapReduce
- Hadoop MapReduce
- Widely used, huge investment already made
- Supports and supported by many complementary tools
- Mature, stable, wellWtested technology
- Skilled developers available
- Spark
- Flexible
- Elegant
- Fast
- Changing rapidly
Hadoop Ecosystem
Data Storage: HBase – The HDFS Database
- HBase: big benifit is you can modify your data
- HBase: database layered on top of HDFS
- Provides interactive access to data
- Stores massive amounts of data
- Petabytes+
- High throughput
- Thousands of writes per second (per node)
- Handles sparse data well
- No wasted space for a row with empty columns
- Limited access model
- Optimized for lookup of a row by key rather than full queries
- No transactions: single row operations only
Data Analysis: Hive
Built on Hadoop MapReduce, an SQL-like access to Hadoop data tool.
Data Analysis: Impala
Open source project, developed by Cloudera, high-speed SQL query engine
- High-performance SQL engine for vast amounts of data
- Similar query language to HiveQL
- 10 to 50+ Gmes faster than Hive or MapReduce
- Impala runs on Hadoop clusters
- Data stored in HDFS
- Dedicated SQL engine; does not depend on Spark, MapReduce, or Hive
Data Integration: Flume
Flume: A service to move large amounts of data in real-time
Spark Streaming is integrated with Flume
Data Integration: Sqoop
Check to see the basic usage for Sqoop