Features
- Spark Streaming provide batch and realtime processing stream data.
- Website monitor
- Fraud detection
- AD monitor
- Much easier than Apache Storm
- Spark provide high-level api
- Storm provide low-level api
- Second-scale latencies
- Once and Only once processing (per duration)
Overview
- Divide up data stream into batches of n seconds
- Process each batch in Spark as an RDD
- Return results of RDD operaBons in batches
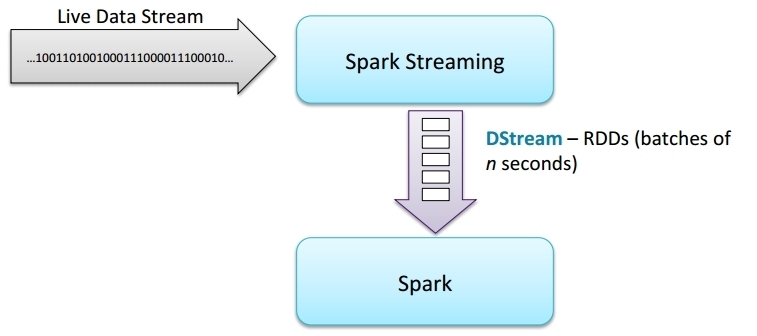
- DStream is serval RDDs in a duration
- Two types of DStream operations:
- Transformations: Create a new DStream from an existing one
- map/flatMap/filter
- reduceByKey/groupByKey/joinByKey
- Output operations: Write data, similar to RDD actions
- print: print first 10 elements in each RDD
- saveAsTextFiles
- saveAsObjectFiles
- foreachRDD(function(RDD,timestamp):xxxxx)
- Transformations: Create a new DStream from an existing one
Running Spark Streaming
when running Spark Streaming, you need to either run the shell on cluster or locally with at least two threads
`spark-shell –master local[2] -i wordcount.scala
otherwise if you use locally with one thread, it will show following error:
15/02/27 10:49:35 WARN BlockManager: Block input-0-1425062975000 already exists on this machine; not re-adding it
15/02/27 10:49:36 WARN BlockManager: Block input-0-1425062975800 already exists on this machine; not re-adding it
15/02/27 10:49:37 WARN BlockManager: Block input-0-1425062976800 already exists on this machine; not re-adding it
Using Window or State need CheckPoint
cd to directory contains pom.xml
use mvn package to compile scala
https://databricks-training.s3.amazonaws.com/index.html
http://databricks.gitbooks.io/databricks-spark-reference-applications/content/index.html
http://www.michael-noll.com/blog/2014/10/01/kafka-spark-streaming-integration-example-tutorial/
Broadcast
https://github.com/JerryLead/SparkInternals/blob/master/markdown/7-Broadcast.md
https://github.com/JerryLead/SparkInternals/tree/master/markdown